My friend Nicola, with whom we often collaborate and whom I thank here, has been studying Akula's code for several months now and recently sent me a paper related to his work: I am very happy to publish the (current) results of his analysis, soliciting readers to express their views and comments.
1. Introduction
Akula (the formal designation is not known) is a communication system used by the Russian navy. Originally Akula was designed as a high speed morse based communication system for submarines to avoid HF direction finding. Various sources set the maximum on-air time for these transmissions to 0.72 seconds. It was not until the USA started deploying the gigantic Wullenweber direction finding antennas that it became possible to triangulate (or multi-angulate) these transmissions.
Today’s Akula normally uses FSK at 500 Baud and a 6-bit alphabet for surface communication links. A
variant called Akula II is a DBPSK burst modem for the use among other in submarine communications.
Other variants have been observed, see Table I below.
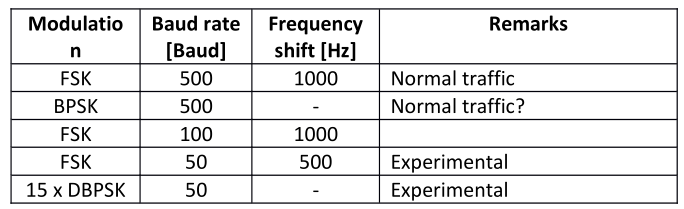 |
| Table I |
Messages intercepted have mostly consisted of encrypted streams, however messages consisting of five
figure groups have also been observed.
2. Alphabet
2.1. Preliminary approaches
Akula utilizes a 6-bit alphabet. Until now 17 different code words have been identified. What the characters represent seems to depend on the message payload format, i.e. five-figure groups or encrypted stream. Ten characters represent the figures from 1 to 9, 6 represent the hex numbers A to F,one represents both a decimal number and SPACE and one is a control character, EOT.
The only code words determined with certainty when these notes were begun, were ’Separator’ (000000 or 11111) and ‘EOT’ (011110 or 011110) marked in green. The codewords representing a decimal figure (0-9) have been determined from a message containing only five figure-groups, but the actual value assigned to a character was not known. However, another interpretation has been done, based on a message perceived as a test transmission in DBPSK modulation.
Table II below shows the 6-bit alphabet in use for Akula consolidating the information available at the time these notes were begun. Characters with the MSB bit set to ‘1’ in normal condition or ‘0’ in inverted condition are part of the number range 0-7, whereas the ones with the MSB bit set to ‘0’ in normal condition or ‘1’ in inverted condition are either within the range 8 – F or is a control character.
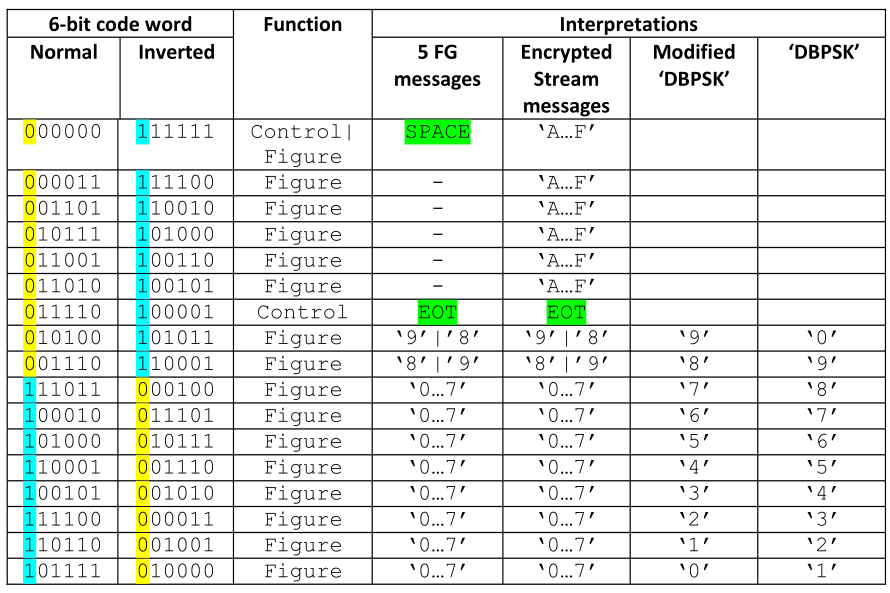 |
| Table II - Akula 6-bit alphabet |
Figure 1 (below, to the left) shows an interpretation, based on the assumption that the message represents the sequence “1 2 3 4 5 6 7 8 9 0” and that the group ‘4443’ in fact represents an error. However, the weak point of this interpretation is the composition of the number sequence. If one let this sequence start at ‘0’ instead of ‘1’ it will be seen that now ‘8’ and ‘9’ both start with a ‘0’ as MSB, which agrees with the previous analysis.
 |
| Fig. 1 |
2.2. Final approach
After investigating the messages available, a new approach was initiated based on the following analysis (1): In a message consisting of five figure groups, 10 different characters in addition to the control characters SPACE and EOT were observed, 8 with an initial ‘0’and 2 with an initial ‘1’, which must represent the numbers ‘0…9’. Analyzing a number of messages with a payload consisting of an encrypted stream identified another 6 characters with an initial ‘1’, which must represent the hexadecimal numbers ‘A…F’.
Going back to the characters identified in the five figure groups, and using the knowledge gained above, the two code words having an initial ‘1’must represent ‘8’ and ‘9’. As SPACE is used as separator between succeeding groups it cannot represent ‘0’. However, this value is mandatory in five figure-groups as well as in encrypted stream messages, thus another code word must represent the value of ‘0’, and logically it should be placed in the range of code words starting with ‘0’, which would correspond to the lower range of hexadecimal figures ordered in descending order.
This could point to an alphabet based on four binary digits plus two check bits. Comparing it to knownmethods of redundancy, a Hamming code can immediately be ruled out as it would require three check bits to protect four data bits. On the other hand, old Soviet radioteletype codes very often used just two check bits to cover 12 data bits.
Now, using the inverted mode of the code words as shown below, and testing various positions of the data bits as exponents of 2 and keeping this together with the position of the parity bits it seemed that one viable guess for the format of an Akula code word could be this:
where d3 = 2^3, d2 = 2^2, d1 = 2^1, d0 = 2^0, p1 = (d3 + d2 + d0) and p0 = (d3 + d2 + d1).
This arrangement is the logical arrangement of hexadecimal figures with the MSB leftmost. Other configurations are entirely possible as long as the MSB is kept as representing 2 3 and the positions of the check bits are fixed. Using this, Table II has been rearranged as shown below:
 |
| Table III - Rearranged Akula alphabet table with parity calculation |
In Table III p0 is marked in turquoise and p1 in yellow. Parity violations are marked in red. The parity inversion for ’0’ may be explained as to avoid a continuous string of binary zero making the extraction of clocking more difficult. The same may make sense for ‘1’ and ‘4’. In the case of EOT the reason could be to establish a unique code word.
Something special surfaced when taking a closer look at a five figure-group message. No code word representing ‘9’ using the power of two calculation given above yielded a ‘9’, which should have been ‘101000’, but a hex ‘B’ ‘101011’ is used for a ‘9’. However, in encrypted stream messages a proper ‘9’ is used.
3. Transmission structure
Below the start of what are considered test messages is depicted.

3.1. Bit sync
Before message transmission starts, bit reversals (a ‘meandr’ in Russian) is transmitted to enable bit synchronization. This is followed by a separator code word (000000 or 11111) or just a number of binary ‘0s’.
3.2. ‘Sync’ group
This group never varies and contains 6 6-bit code words from the figures range arranged as 4 x 100101 + 3 x 110001 followed by a separator:
100101
100101
100101
100101
110001
110001
000000
Polarity is shown in normal mode.
3.3. ‘Preamble’ group
The ‘preamble’ group contains 7 code words with two different, but varying values arranged as 4 x 1st code word + 3 x 2nd code word. If data following the ‘preamble’ group is encoded as 5 figure groups, the preamble is followed by a separator code word. Polarity is shown in normal mode. Given the information in Table IV, it is clear that the group cannot be a bit counter as the preamble group covers four different message lengths.
 |
| Table IV |
3.4. Message format
Data may be transmitted either as five figure-groups separated by a separator character or a stream of characters. In the first case, a separator character also separates the data group from the End-Of-Message group. If data is encoded as a stream, all 16 6-bit characters are used, except EOM, and data is not separated from the EOM group by a separator code word.
3.5. End-Of-Message group
Polarity is shown in inverted mode.
010000 0
011101 6
011101 6
010000 0
100001 EOT
3.5.1. EOT character
The EOM group ends with an EOT character, 100001.
4. Unresolved issues
- Confirmation of the proper arrangement of the d2, d1 and d0 data bits;
- Is the ‘Sync’ group in fact a synchronization group, i.e. is it the same for all messages disregarding priority, contents …? (the reason for raising this issue is the simplicity of this group – normally a synchronization group or unique word would be constructed in such a way and with such a length to obtain optimum resilience against distortions and noise);
- The function of the ‘preamble’ group.
No comments:
Post a Comment